山东一建建设有限公司网站企业网站seo托管怎么做

默认跳过基础部分,直接搞集群的部分,期间用到的linux基础默认大伙都会了(不会的话可以现用现查)
Hadoop集群搭建
集群特点:
1,逻辑上分离~集群之间没有依赖,互不影响
2,某些进程往往部署在一台服务器上,但是属于不同的集群
3,MapReduce 是计算框架,代码层面的处理逻辑
集群的搭建
集群角色的规划:
- 根据软件工作特性跟服务器硬件资源来做分配
- 资源上有冲突的尽量不要部署在一起
- 工作上相互配合的,尽量部署在一起
服务器基础环境准备
研究一下官网给的教程:
需要 java环境
因为hadoop是根据java语言编写的,所以需要java环境支持
安装java环境过程略
 hadoop不同的版本是对java版本有一定要求的
hadoop不同的版本是对java版本有一定要求的
支持的 Java 版本
Apache Hadoop 3.3 及更高版本支持 Java 8 和 Java 11(仅限运行时)
请使用Java 8编译Hadoop。不支持使用 Java 11 编译 Hadoop: HADOOP-16795 - Java 11 编译支持 打开
Apache Hadoop 从 3.0.x 到 3.2.x 现在仅支持 Java 8
Apache Hadoop 从 2.7.x 到 2.10.x 同时支持 Java 7 和 8
ssh加密
安装openssh-client 和 openssh-server
过程略

配置hadoop的环境参数
下载hadoop压缩包
这里选择稳定的版本 stable2
wget https://dlcdn.apache.org/hadoop/common/stable2/hadoop-2.10.2.tar.gz
下载后解压
tar -zxf hadoop-2.10.2.tar.gz

编辑配置文件
 在配置文件中我们可以看到需要我们 配置java_home
在配置文件中我们可以看到需要我们 配置java_home
root@Gavin:/usr/local/hadoop-2.10.2/etc/hadoop# vi hadoop-env.sh
root@Gavin:/usr/local/hadoop-2.10.2/etc/hadoop# export JAVA_HOME=/usr/local/java/jdk11
root@Gavin:/usr/local/hadoop-2.10.2/etc/hadoop# java -version
openjdk version "1.8.0_352"
OpenJDK Runtime Environment (build 1.8.0_352-8u352-ga-1~20.04-b08)
OpenJDK 64-Bit Server VM (build 25.352-b08, mixed mode)
root@Gavin:/usr/local/hadoop-2.10.2/etc/hadoop# javac -version
javac 1.8.0_352
准备启动hadoop集群
hadoop支持三种模式启动
本地(独立)模式
先来一个本地启动吧
默认情况下,hadoop配置为非分布式模式下运行,作为单个的java 进程,这对于调试很有用,因为默认的打包并不适合所有的场景,企业一般需要自己订制(所以企业也不会像我这样直接下载打包好的tar包使用,而是直接下载源码进行适当修改后在编译;
按照惯例先看帮助文档

root@Gavin:/usr/local/hadoop-2.10.2# mkdir input
root@Gavin:/usr/local/hadoop-2.10.2# cp etc/hadoop/*.xml input
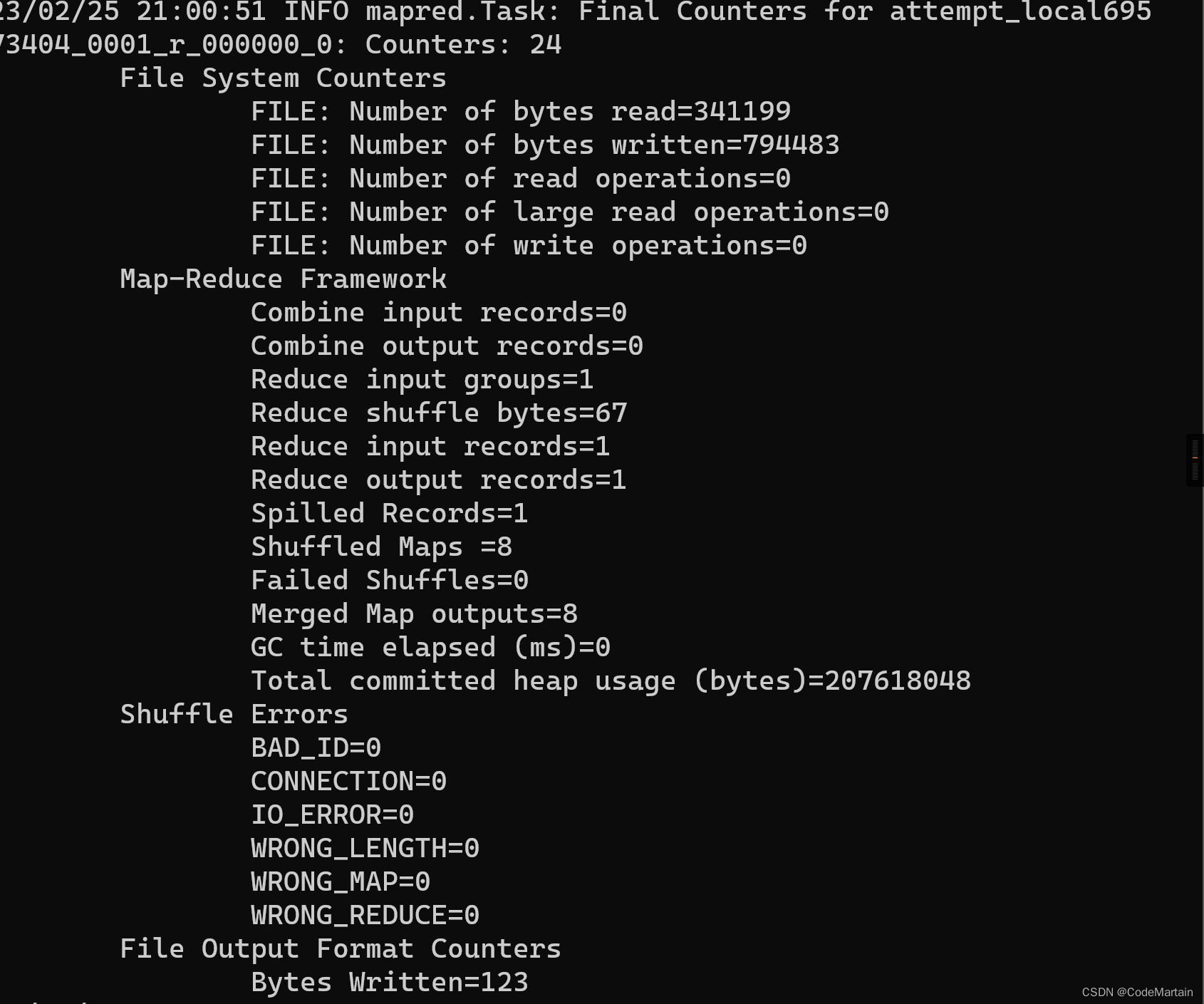
root@Gavin:/usr/local/hadoop-2.10.2# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.2.jar grep inp
ut output 'dfs[a-z]+'
最后的结果~
 不知道是否正确,按照目前的情况来看,之前是没有input 和output 文件夹的
不知道是否正确,按照目前的情况来看,之前是没有input 和output 文件夹的
MapReduce的运作模式~大致如下
伪分布式操作
配置核心的参数

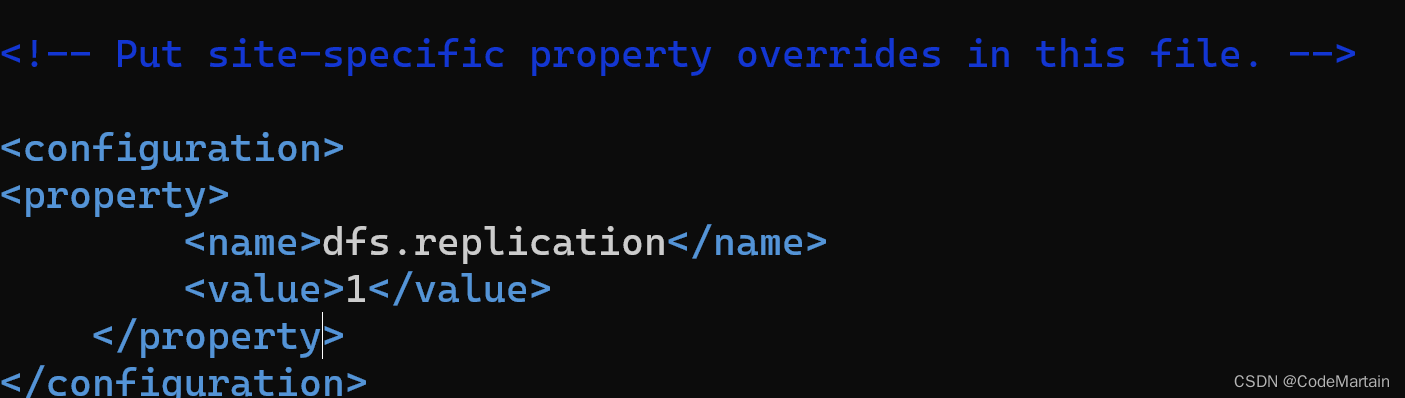
找到以下文件
etc/hadoop/core-site.xml:

etc/hadoop/hdfs-site.xml:
未完待续,先看看理论在继续